What is Kafka?
Let’s start this Kafka 101 series off with some definitions. On the homepage of Apache Kafka, Kafka is described as a distributed streaming platform. To people having little or no experience with streaming data, they could immediately think of audio or video streaming service like Spotify and Netflix. Nevertheless, the term streaming here, although bearing similarity to these streaming services to some extent, refers to a much wider scope of data stream.
Streaming data in general is the unbounded flow of data coming continuously from numerous data sources. One example is a smart sensor network consisting of different sensors such as humidity, air pressure and air quality; these sensors will continuously send out measurements to processing units to monitor the environment in a manufacturing line. Temporal order in streaming data is usually very important since it is a key indicator of the change and trend of data over time. Therefore, streaming data needs to be received and processed as new data record arrives in a continuous and sequential fashion to provide real-time analysis of the data and enable prompt reaction. Some more examples of streaming data application are: network traffic monitoring, financial trading floors, customer interactions in a webpage monitoring.
Kafka, as its official definition suggested, provides the basis necessary to build up application for processing stream of data, or stream of records as being called in Kafka documentation. Kafka facilitates the transmitting, storing and processing of streaming records. In order to do that, Kafka runs as clusters spanning one or more server and plays the role in the manner of a distributed message broker in charge of storing and transmitting records stream between Kafka clients and other data systems.
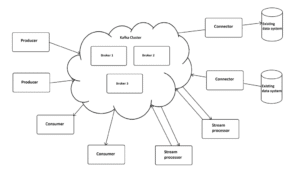
Kafka cluster can be hosted on-premises or can be used directly from Kafka cloud service providers such as Confluent and Cloudkarafka. On top of that, Kafka provides some core APIs:
- Producer API and Consumer API: to build up Kafka clients that can publish and consume records on Kafka cluster.
- Streams API: to build application being able to read from Kafka cluster, do analysis, enrich data and then publish it back to the cluster. Moreover, it provides sturdy stream processing capabilities such as stream transformation, windowing processing, stateful operations with queryable and fault-tolerant state store. Kafka Streams API also defines clear semantics of time, namely, event time, ingestion time and processing time, which is very important for stream processing applications.
- Connector API: to build up connectors linking Kafka cluster to different data sources such as legacy database.
Confluent Platform, which is built on top of the open-source Kafka with both Community and Enterprise licenses, provides additional robust features such as ready-to-be-used connectors, stream processing using SQL-like semantics with KSQL, monitoring and managing tool of Kafka cluster, auto data balancer. This streaming platform is believed to make developing and managing applications running around Kafka faster and easier. Thus, Confluent Platform and its additional features could be discussed and assessed in more detail in a later blogpost.
Some key concepts of Kafka
In order to know the differences between Kafka and traditional messaging systems, we have to take a look into how Kafka store and manage stream of records. The records published to Kafka cluster are divided into different categories called topics. Kafka cluster maintains each topic in a partitioned log format in order to guarantee within each partition of the log the order of records when they were written to the topic. A more detail explanation of the log can be found here. The records will be stored in each partition in the order they arrive with the new record be appended at the end of the partition. This order cannot be changed. Each record will be labeled with a specific number called offset which is the indicator of its position in the log as well. Publisher can choose which partition to publish records to. If no partition is explicitly specified, the partition to which the record is published is decided based on the key of the record by default. This feature helps ensure that records with the same key will always be published to the same partition and hence their temporal order is preserved. The concept of dividing topics into smaller partitions yields a number of advantages:
- Scalability: a topic can have a size bigger than the storage capability of a server. In this case, the topic will be stored in several servers, each server will hold a subset of complete partitions of the topic.
- Parallelism: a topic can be processed by different consumers simultaneously with each consumer uniquely processes specific partitions in the topic.
- Fault-tolerance: there are 2 types of partitions, leader and follower. While clients will read and write to leader partition only, follower partitions are replications of the leader and distributed on different server node in the cluster and can be used to replace leader partition in case of server broken down. This process of failover is managed and done automatically by Kafka and is completely transparent to developers.
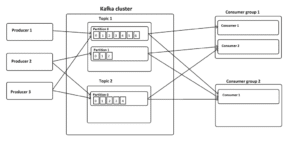
All records will be kept on Kafka cluster for a configured time period. It is also possible to set this retention period to infinite to store records permanently. During this period, a consumer can read every records in the partitions which are assigned to it using the offset number. Moreover, the information about the position of the record under processed is controlled and maintained by each consumer itself rather than Kafka. As a result, the Kafka cluster and consumers are better decoupled. New consumer can subscribe to a topic and start to process the entire history of records in storage without having much impact on the cluster or other consumers.
Consumers are grouped into different consumer groups. Each group can subscribe to one or more topic. The partitions in the topic will be distributed among consumers in the group. Therefore, the number of consumers in a group can be altered to provide necessary parallel processing. Kafka manages the distribution of partitions to consumers dynamically:
- Number of consumers in a group = number of partitions: each consumer consumes a partition.
- Number of consumers in a group > number of partitions: some consumers will be idle.
- Number of consumers in a group < number of partitions: some consumers will consumes more partitions than others.
What are the differences between Kafka and traditional messaging systems?
When talking about traditional messaging systems, there are two major domains: Message Queue (Point-to-Point Messaging) and Publish/Subscribe Messaging.
Message Queue: the first and apparent difference is that message will be deleted from the queue after receiving confirmation from consumer while in Kafka, records will be kept until the retention period expires. Secondly, multi-subscriber for different kind of processing on the message is not possible for message queue while it is feasible in Kafka via consumer group concept. In both systems, horizontal scalability is possible by adding more than one consumer to a queue in the case of Message Queue and adding more consumers in one group in Kafka. However, in Message Queue, it is important that every message gets consumed by one consumer. Other than that, messages can reach consumers differently and out-of-order even though they arrive at the queue with the right temporal order. In Kafka, the order of records being read in a partition is guaranteed since each partition is read by only one consumer.
Publish/Subscribe Messaging: inspecting on an abstract level, Kafka uses Publish/Subscribe concept in its core. Both systems can be used to delivered message to multiple subscribers. In Publish/Subscribe Messaging, messages can also be retained using durable subscription as well. Nevertheless, looking deeper into the implementation, horizontal scalability in Publish/Subscribe is not possible since message will be sent to every subscriber of the topic. On the other hand, with Kafka, multi-subscriber can be achieved via consumer groups and scalability is possible in each group with the concept of partition.
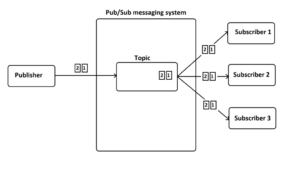
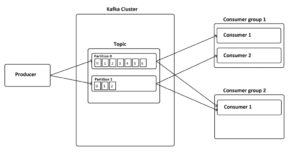
As can be seen from the image, for Publish/Subscribe messaging, all subscribers will receive the same messages published to the topic by publisher. In Kafka, all consumer groups subscribed to the topic can read from it. Moreover, in consumer group 1, there are two competing consumers 1 and 2 reading in parallel from partition 0 and 1. In case of growing topic, more consumers can be added to each consumer group to process the topic faster.
Summary
In this blogpost, we have determined what Kafka is and looked through some of its concepts. A comparison between Kafka and old messaging system has been drawn out as well. In subsequent blogposts in this series, we will continue to go through more topics of Kafka like stream processing and Kafka Streams API, how to build up a simple application using Kafka, and discussion about Confluent Platform.


